Successful Examples in EmbodiedBench powered by GPT-4o: EB-Manipulation (left) and EB-Navigation (right).
Failure Examples in EmbodiedBench powered by GPT-4o: EB-Manipulation (left) and EB-Navigation (right).
We introduce EmbodiedBench, a comprehensive benchmark designed to evaluate Multi-modal Large Language Models (MLLMs) as embodied agents. While existing benchmarks have primarily focused on Large Language Models (LLMs) and high-level tasks, EmbodiedBench takes a leap forward by offering a comprehensive, fine-grained evaluation of MLLM-based agents across both high-level and low-level tasks, as well as six critical agent capabilities.
EmbodiedBench is more than just a benchmark-it's a multifaceted, standardized evaluation platform that not only uncovers the current challenges in embodied AI but also provides actionable insights to push the boundaries of MLLM-driven embodied intelligence.
EmbodiedBench is designed with two key features that set it apart from existing benchmarks: 1. Diverse tasks with hierarchical action levels. Among the four environments, EB-ALFRED and EB-Habitat focus on high-level task decomposition and planning (e.g., "put a book on the desk" ), while EB-Navigation and EB-Manipulation demand planning with low-level actions (e.g., translational/rotational control ) and require precise perception and spatial reasoning. 2. Capability-oriented evaluation. Unlike previous benchmarks that primarily emphasize overall accuracy or module-specific performance, EmbodiedBench introduces a fine-grained evaluation framework that assesses six critical capabilities of embodied agents, including basic task solving, commonsense reasoning, complex instruction understanding, spatial awareness, visual perception, and long-horizon planning.
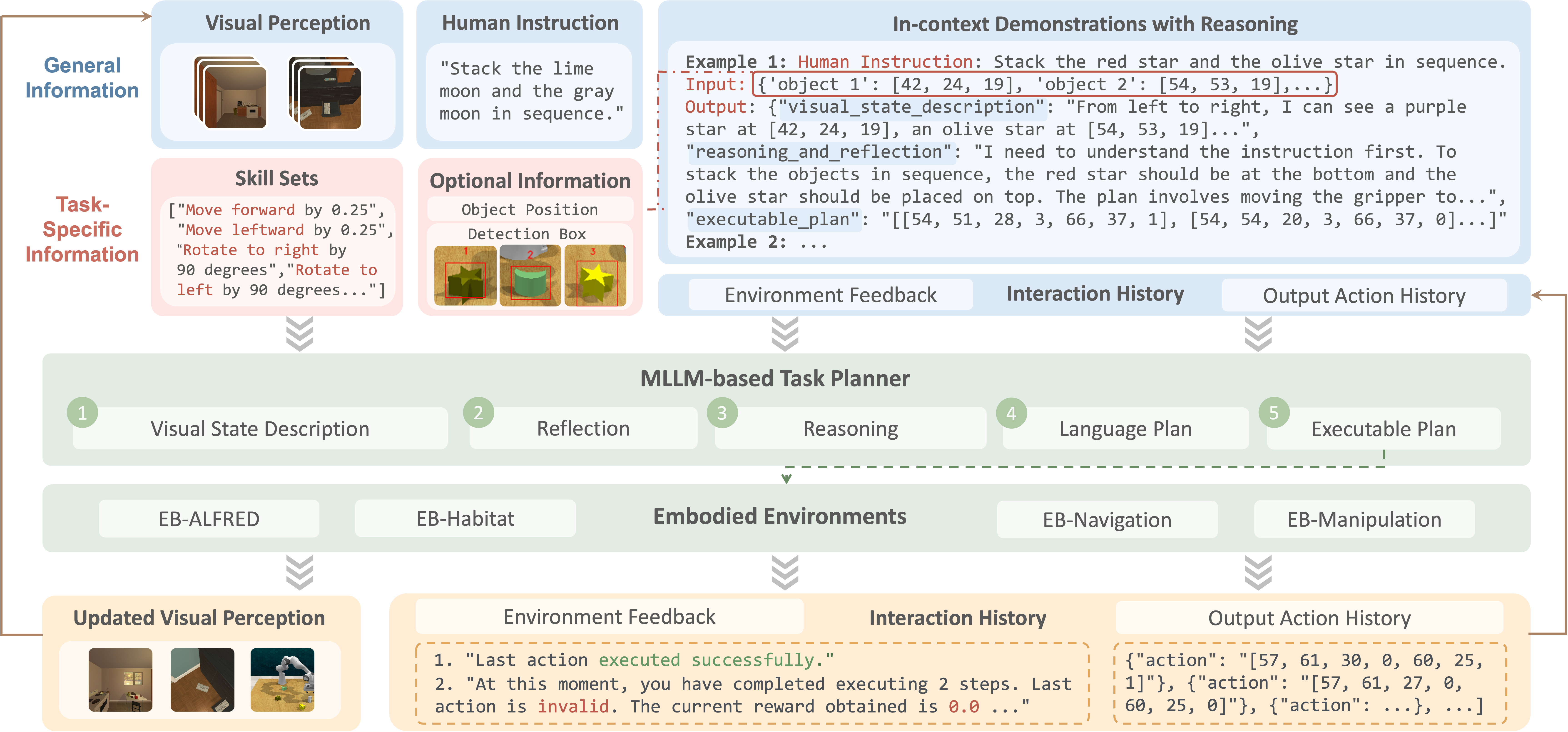
To evaluate MLLMs as agents in EmbodiedBench, we design a unified embodied agent pipeline, illustrated in Figure 2. This pipeline provides a robust framework for processing multimodal inputs, reasoning through interactions, and generating structured, executable plans composed of sequential actions.
In this section, We conducted an error analysis on GPT-4o to identify potential failure modes. For each environment, we sample 10 failure episodes from each subset, resulting in a total of 110 failed episodes to be analyzed. We found three main types of errors: perception errors, reasoning errors, and planning errors. Each error type corresponds to a specific stage in our agent pipeline. For example, perception errors occur during the visual state description stage, reasoning errors arise in the reflection and reasoning stages, and planning errors occur during the language plan and executable plan generation stages.
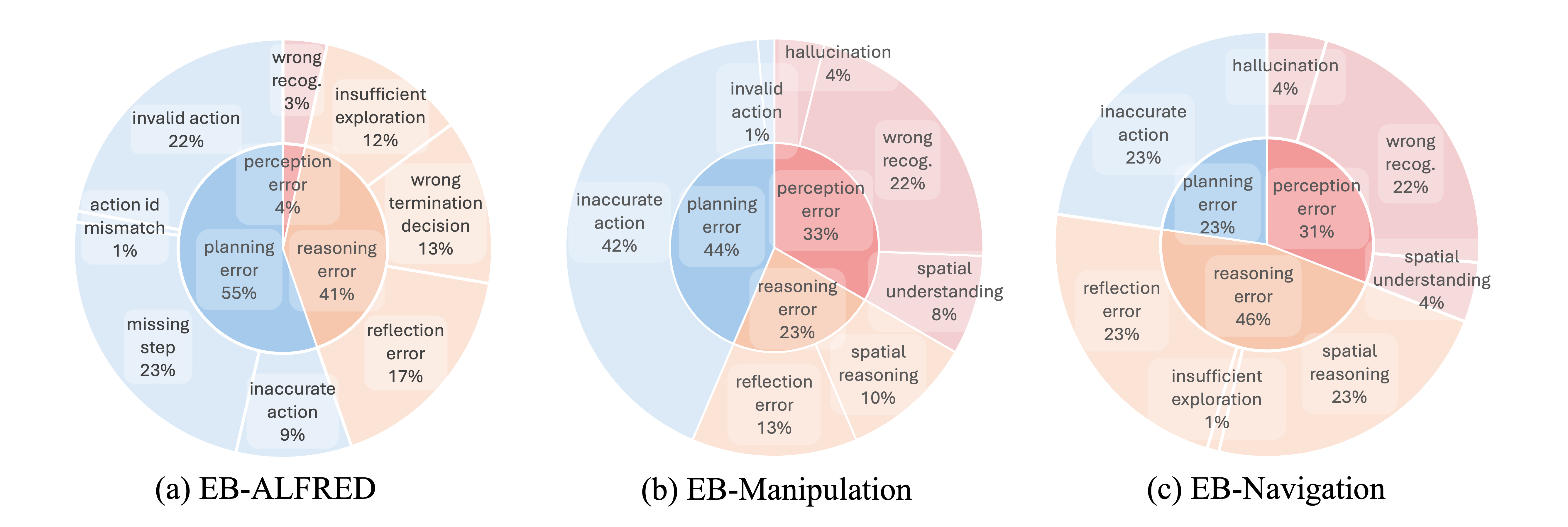

Figure 4. Planning example of Claude-3.5-Sonnet in EB-ALFRED.

Figure 5. Planning example in EB-Habitat for InternVL2.5-78B.

Figure 6. Planning example of GPT-4o in EB-Navigation.

Figure 7. Planning example of Gemini-1.5-pro in EB-Manipulation.

Figure 8. Planning Error Example in EB-ALFRED: The agent was supposed to locate "Book_2" by the 7th action but instead continued interacting with the first book.
Figure 9. Perception Error Example in EB-Manipulation: the agent erroneously observed the color of the object.

Figure 10. Reasoning Error Example in EB-Navigation: the agent recognized it was blocked by the countertop but failed to attempt navigating around it.
@article{yang2025embodiedbench,
title={EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents},
author={Yang, Rui and Chen, Hanyang and Zhang, Junyu and Zhao, Mark and Qian, Cheng and Wang, Kangrui and Wang, Qineng and Koripella, Teja Venkat and Movahedi, Marziyeh and Li, Manling and others},
journal={arXiv preprint arXiv:2502.09560},
year={2025}
}



